

Η πρόοδος στα Μεγάλα Γλωσσικά Μοντέλα (LLMs) έχει βασιστεί ουσιαστικά στη χρήση τεράστιων ποσοτήτων ανθρώπινης παραγόμενης κειμενικής πληροφορίας. Η μελέτη “Will we run out of data?” των Pablo Villalobos, Anson Ho, Jaime Sevilla και συνεργατών , εξετάζει το ενδεχόμενο εξάντλησης αυτής της πληροφορίας ως εμπόδιο για τη μελλοντική κλιμάκωση των LLMs.
Μέσα από εμπειρική ανάλυση και μαθηματική μοντελοποίηση, οι συγγραφείς προβλέπουν ότι, αν συνεχιστούν οι τρέχουσες τάσεις ανάπτυξης, το σύνολο των διαθέσιμων δημόσιων ανθρώπινων δεδομένων θα έχει πλήρως αξιοποιηθεί μεταξύ 2026 και 2032. Η μελέτη επίσης εξετάζει εναλλακτικές λύσεις για την αντιμετώπιση αυτής της πρόκλησης, όπως η σύνθεση δεδομένων από τεχνητά συστήματα, η μεταφορά μάθησης από άλλες περιοχές και η αύξηση της αποδοτικότητας στη χρήση δεδομένων.
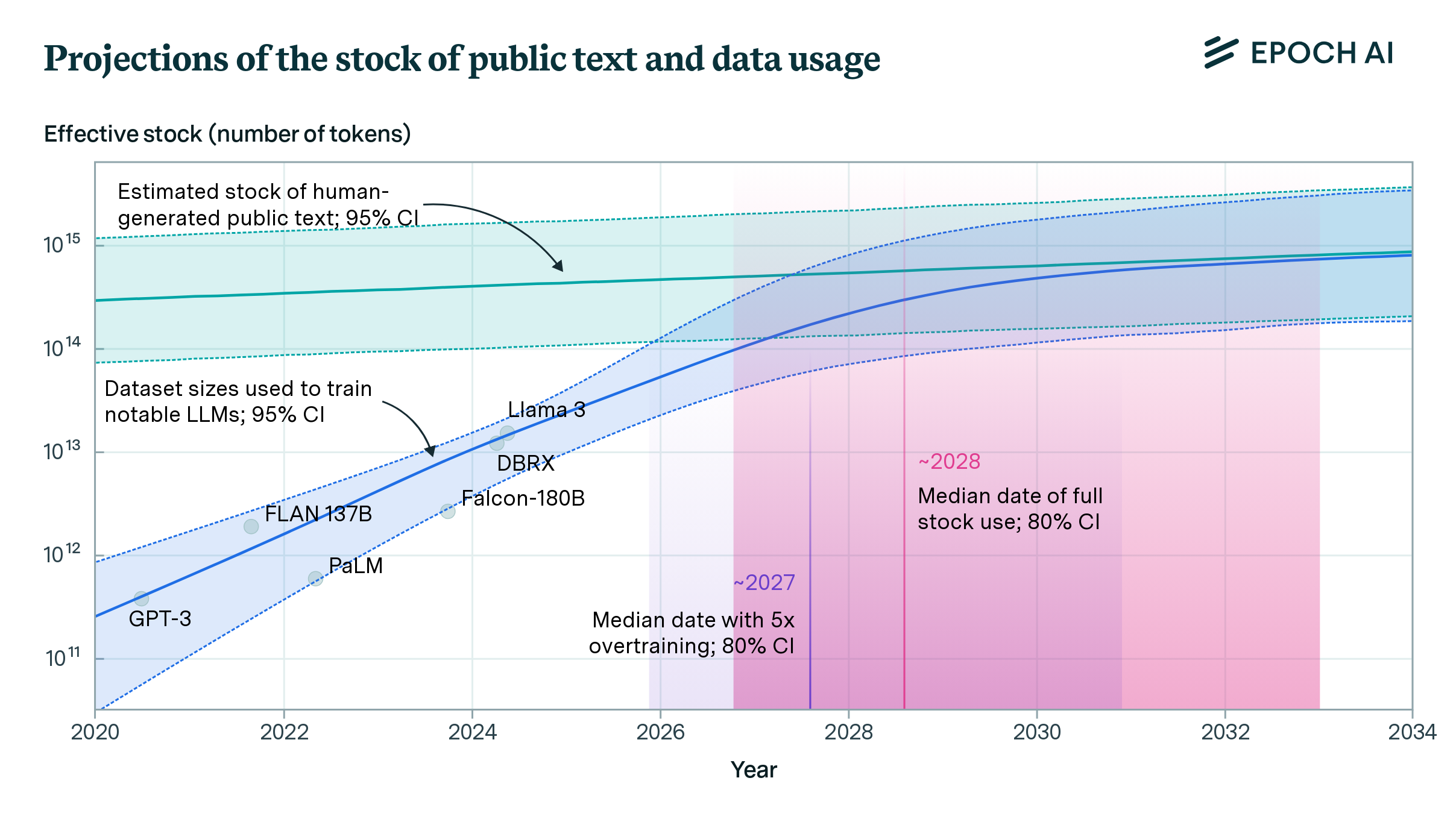
Η Τρέχουσα Κατάσταση των Δεδομένων
Η μεγάλη πλειονότητα των LLMs εκπαιδεύεται με βάση μη επιβλεπόμενη μάθηση από δεδομένα που συλλέγονται από πηγές όπως το Common Crawl, τα Wikipedia dumps, και άλλες δημόσιες πλατφόρμες. Σύμφωνα με τις εκτιμήσεις των συγγραφέων, ο συνολικός όγκος των ανθρώπινων παραγόμενων κειμένων στον ιστό (indexed web) κυμαίνεται γύρω στα 510 τρισεκατομμύρια tokens, με το άνω όριο για ολόκληρο το διαδίκτυο να φθάνει ως και τα 3.100 τρισεκατομμύρια tokens.
Όμως, τα διαθέσιμα αυτά δεδομένα παρουσιάζουν τρία προβλήματα:
- Ποιότητα: πολλά δεδομένα θεωρούνται χαμηλής ποιότητας και δεν βελτιώνουν την απόδοση των μοντέλων.
- Επανάληψη: για να ενισχυθεί η εκπαίδευση, γίνεται χρήση πολλαπλών εποχών (multi-epoch training), πολλαπλασιάζοντας τη χρήση του ίδιου συνόλου δεδομένων.
- Φιλτράρισμα: η χρήση αλγορίθμων φιλτραρίσματος (π.χ. perplexity) αποκλείει μεγάλο μέρος των δεδομένων.
Η τελική «ποιοτικά προσαρμοσμένη» και «επαναληπτικά προσαρμοσμένη» αποθήκη δεδομένων φθάνει περίπου τα 320 τρισεκατομμύρια tokens.
Προβλέψεις Κατανάλωσης Δεδομένων
Η ιστορική ανάλυση αποκαλύπτει ότι ο ρυθμός αύξησης των dataset που χρησιμοποιούνται σε μοντέλα LLM είναι 0.38 OOM ανά έτος, δηλαδή σχεδόν 2.4 φορές περισσότερα δεδομένα κάθε χρόνο. Συνδυάζοντας την ιστορική τάση με τον προβλεπόμενο ρυθμό αύξησης της διαθέσιμης υπολογιστικής ισχύος, οι συγγραφείς προβλέπουν ότι:
- Το σύνολο των διαθέσιμων ανθρώπινων δεδομένων θα έχει καταναλωθεί μέχρι το 2028.
- Αν επιλεγεί πολιτική υπερεκπαίδευσης (5x overtraining), η εξάντληση θα προκύψει νωρίτερα, ίσως το 2027.
Η εκπαίδευση με τόσο μεγάλο όγκο δεδομένων προϋποθέτει 5e28 FLOPs, ποσότητα που αναμένεται να είναι διαθέσιμη προς τα τέλη της δεκαετίας.
Εναλλακτικές Προσεγγίσεις μετά την Εξάντληση
Συνθετικά Δεδομένα (AI-generated data)
Η παραγωγή συνθετικών δεδομένων μέσω των ίδιων των μοντέλων αναδεικνύεται σε βασική στρατηγική. Παρά τα προβλήματα υποβάθμισης ποιότητας (π.χ. model collapse), σε πεδία όπως ο προγραμματισμός και τα μαθηματικά η αυτοπαραγόμενη εκπαίδευση αποδίδει εξαιρετικά (π.χ. AlphaZero, AlphaGeometry).
Μεταφορά Μάθησης & Πολυτροπικά Μοντέλα
Η μεταφορά γνώσης από δεδομένα άλλων μορφών (π.χ. εικόνες, βίντεο, γενωμικά δεδομένα) ανοίγει νέους δρόμους. Παρόλο που τα περισσότερα τέτοια δεδομένα δεν επαρκούν ποσοτικά, η συνεργατικότητα (synergy) με κείμενο είναι πολλά υποσχόμενη — όπως φαίνεται σε multimodal μοντέλα τύπου GPT-4V.
Μη-δημόσια Δεδομένα
Οι κλειστές πλατφόρμες κοινωνικής δικτύωσης και τα μηνύματα περιέχουν δεκάδες τετράκις εκατομμύρια tokens. Η χρήση τους, όμως, εγείρει σοβαρά ζητήματα προσωπικών δεδομένων, νομικής φύσεως και αμφίβολης ποιότητας περιεχομένου.
Συμπεράσματα
Η προβλεπόμενη εξάντληση των δημόσιων ανθρώπινων δεδομένων δεν σημαίνει το τέλος της εξέλιξης των LLMs. Αντίθετα, λειτουργεί ως ένα προειδοποιητικό όριο που καλεί την επιστημονική κοινότητα να εξελίξει μεθόδους όπως:
- Αποτελεσματικότερη εκμετάλλευση δεδομένων μέσω τεχνικών pruning, curriculum learning, domain composition.
- Ανάπτυξη επαρκώς διαφοροποιημένων συνθετικών δεδομένων, συνδυάζοντας ανθρώπινα και τεχνητά inputs.
- Μηχανισμοί προσαρμοστικής μάθησης από τον πραγματικό κόσμο, όπως αλληλεπιδράσεις με χρήστες ή περιβάλλοντα.
Η συνεχιζόμενη αύξηση του μεγέθους των LLMs αναπόφευκτα συγκρούεται με τον πεπερασμένο χαρακτήρα της ανθρώπινης κειμενικής πληροφορίας. Αν και το φαινόμενο δεν οδηγεί αναγκαστικά σε στασιμότητα της προόδου, χρειάζεται μεταστροφή του ερευνητικού παραδείγματος, με έμφαση σε τεχνικές σύνθεσης, αποδοτικότερης χρήσης και διεύρυνσης του τύπου των δεδομένων.
Η επόμενη εποχή στην τεχνητή νοημοσύνη απαιτεί ποιοτική καινοτομία στη μάθηση, όχι απλώς αύξηση όγκου.
Διαβάστε την πλήρη μελέτη εδώ